종강과 함께 돌아온 ! AI 스터디 1팀 네번째 주자입니다.
한달 전에 머물러있던 기억을 끄집어내서 ,, 잘 써보겠습니다 😎
⭐ 모든 소스 코드는 https://github.com/deeplearningzerotoallgithub.com/deeplearningzerotoall/TensorFlow/tree/master/tf_2.x 에서 확인 가능합니다. (Tensorflow 2.x 기준)
XOR 문제
이번주 내용에 본격적으로 들어가기 전, 먼저 단일 신경망의 XOR 문제에 대해 복습해보겠습니다.
(오늘의 TMI : 이 문제는 인공지능 분야에 암흑기를 가져온 사건 중 하나다)
- 두 입력 x1, x2가 들어온다고 가정할 때 AND, OR 연산은 하나의 직선으로 데이터를 분류할 수 있지만 XOR 연산은 하나의 직선만으로는 데이터 분류 불가능
- '하나의 직선'이란 위에서 언급한 단일 신경망을 의미하며 퍼셉트론 한 개를 뜻하기도 함

딥러닝을 이용한 XOR 문제 해결
- 단일 신경망으로 XOR 문제를 해결할 수 없기 때문에 신경망을 여러 층으로 쌓는 구조(multi-layer) 제시
- x1, x2에서 바로 결과값을 얻어내는 게 아니라 중간 과정을 만드는 작업

결론
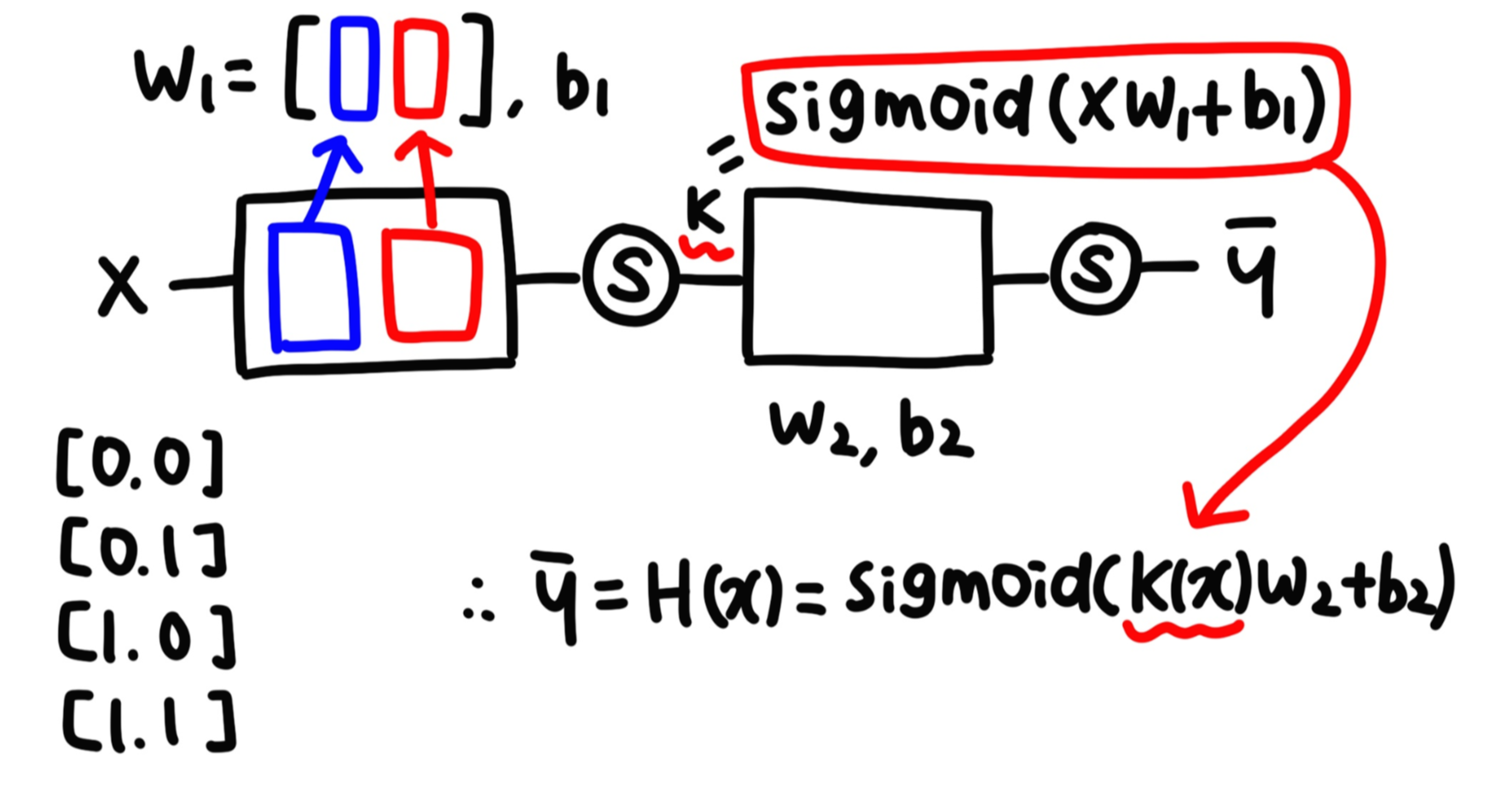
w1 : multi-nomial(다항분포)을 이용해서 두 개의 가중치를 하나의 2차원 행렬로 표시
(바로 윗 부분에 있는 딥러닝을 이용한 XOR 문제 해결의 그림으로 설명을 하자면 파란색은 y1 출력에 사용되는 가중치, 빨간색은 y2 출력에 사용되는 가중치)
데이터 학습시키기
w1, w2, b1, b2를 찾으려면 입력 x가 출력 y에 어떤 영향을 끼치는지 알아야 하고 각각의 데이터에 대한 미분값이 필요한데, 여러 층이 쌓이게 되면서 미분값을 하나하나 찾아주는 것이 너무 많은 연산을 필요로 하기 때문에 값 찾기가 어려운 상태
* 신경망 네트워크 구현(Tensorflow)
def neural_net(features):
layer1 = tf.sigmoid(tf.matmul(features, W1)+b1)
layer2 = tf.sigmoid(tf.matmul(features, W2)+b2)
hypothesis = tf.sigmoid(tf.matmul(tf.concat([layer1, layer2], -1), W3)+b3)
return hypothesis
Relu
sigmoid 함수는 값을 0, 1로만 나타낸다는 점에서 편리하지만 gradient vanishing 현상(gradient=0이 곱해져서 다음 레이어로 전파되지 않음)이 일어나면서 학습에 치명적인 문제가 발생 → sigmoid 함수의 대안으로 사용하는 함수가 Relu 함수
* Relu 구현(Tensorflow)
# Tensorflow로 구현
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
tf.enable_eager_execution()
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32)
test_data = test_data.astype(np.float32)
return train_data, test_data
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1)
test_data = np.expand_dims(test_data, axis=-1)
train_data, test_data = normalize(train_data, test_data)
# One hot incoding
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
return train_data, train_labels, test_labels
# create network
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(units=channel, use_bias=True, kernel_initializer=weight_init)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.RandomNormal()
self.model = tf.keras.Sequential()
self.model.add(flatten())
for i in range(2):
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dense(label_dim, weight_init))
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def create_model(label_dim):
weight_init = tf.keras.initializers.RandomNormal()
model = tf.keras.Sequential()
model.add(flatten())
for i in range(2):
model.add(dense(256, weight_init))
model.add(relu())
model.add(dense(label_dim, weight_init))
return model
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels))
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
#Dataset
train_x, train_y, test_x, test_y = load_mnist()
#Parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x)
label_dim = 10
#Graph input using dataset API
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
#Dataset iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
#Model
network = create_model(label_dim)
#Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(grads_and_vars=zip(grads, network.variables), global_step=global_step)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_labels)
print("Epoch: [%2d] [%5d/%5d], train_loss: %.8f, train_accuracy: %.4f, test_Accuracy: %.4f" \
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy))
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + '-{}'.format(counter))
가중치 초기화
딥러닝 학습에 있어 초기 가중치 설정은 매우 중요한데 가중치를 잘못 설정할 경우 기울기 소실 문제나 표현력의 한계를 갖는 등 여러 문제를 야기
< 잘못된 가중치 초기화 >
① 초기값을 모두 0으로 설정한 경우
② 활성화 함수로 sigmoid 선택 시 정규분포를 사용하는 경우
③ ②번에서 표준편차를 줄이는 경우
Xavier Initialization
기존의 가중치는 Random normal initialization을 사용해 평균 0, 분산 1이었지만 Xavier는 평균 0, 분산 2/(input 채널 개수+output 채널 개수)로 가중치를 초기화 → fan in, fan out을 모두 고려하여 확률 분포를 조정하는 방법
Drop-out

under-fitting을 피하고, over-fitting을 막기 위한 Regularization의 방법 중 하나로 모든 노드를 학습에 사용하는 것이 아니라 일부 노드만 이용해 학습을 진행
Batch Normalization
Gradient Vanishing / Gradient Exploding 문제를 방지하기 위해 학습 과정 자체를 전체적으로 안정화하여 학습 속도를 가속시키는 방법으로, 평균과 분산을 조정하는 과정이 별도의 과정으로 떼어진 것이 아니라 신경망 안에 포함되어 학습 시 평균과 분산을 조정하는 과정이 같이 조절됨
* Batch Normalize 구현(Tensorflow)
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_date
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1)
test_data = np.expand_dims(test_data, axis=-1)
train_data, test_data = normalize(train_data, test_data)
# One hot incoding
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
return train_data, train_labels, test_labels
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(units=channel, use_bias=True, kernel_initializer=weight_init)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
def batch_norm():
return tf.keras.layers.BatchNormalilzation()
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten())
for i in range(2):
self.model.add(dense(256, weight_init))
self.model.add(batch_norm())
self.model.add(relu())
self.model.add(dense(label_dim, weight_init))
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels))
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
#Dataset
train_x, train_y, test_x, test_y = load_mnist()
#Parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x)
label_dim = 10
#Graph input using dataset API
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
#Dataset iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
#Model
network = create_model(label_dim)
#Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(grads_and_vars=zip(grads, network.variables), global_step=global_step)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_labels)
print("Epoch: [%2d] [%5d/%5d], train_loss: %.8f, train_accuracy: %.4f, test_Accuracy: %.4f" \
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy))
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + '-{}'.format(counter))
Batch Normalization을 마지막으로 4주차 강의 정리를 마치도록 하겠습니다 !
이해가 잘 가지 않거나 이번 학습 내용을 가지고 함께 의견을 나눠보고 싶은 분이 계시다면 댓글 남겨주세요 :)

'AI' 카테고리의 다른 글
| [AI-3Team] 다변수 선형 회기(Multi Variable Linear Regression) (0) | 2020.12.29 |
|---|---|
| [AI-3Team] Logistic Regression (0) | 2020.12.27 |
| [ai-3team] Study_2: Linear Regression and Optimization (0) | 2020.11.26 |
| [ai-1team] 3. Application & Tips (0) | 2020.11.21 |
| [ai-1team] 2. Logistic Regression (0) | 2020.11.13 |



