Learning rate
가장 최적화된 모델을 찾기 위한 과정은 적절한 Learning rate 값을 찾아 Gradient 값이 0이 되는 지점을 찾는 것이다.
학습이 진행됨에 따라 cost 값이 점차 줄어들수록 학습능률이 좋은 모델이다.


Learning rate 가 너무 큰 값일 경우 오른쪽 그래프의 붉은 표시와 같이 값을 과하게 이동하며 실행되고, overshooting 현상이 발생할 수 있다.
반대로 Learning rate 값이 너무 작을 경우, 실행 시간이 오래 걸릴 수 있기 때문에 적절한 값을 찾아 설정해야한다.
Learning rate 값은 주로 0.01이 사용되고, Adam Optimizer에서 최적의 Learning rate 값은 3e-4이다.

학습을 하는 과정에서 cost 값이 더 이상 내려가지 않는 경우가 있는데, 이 경우 Learning rate 값을 조정하여 학습을 계속해서 진행할 수 있게 해주어야 한다. 이를 Learning rate decay라 한다.
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
1000, 0.96, staircase = True)
# tf.train.exponential_decay(시작 값, 전체 스텝, n번째마다, 0.nn의 비율로) 위와 같은 코드를 작성해 Learning rate 값을 정해진 간격마다 조절할 수 있다.
Data preprocessing
다음은 데이터 전처리에 대한 내용이다.

왼쪽의 그래프와 같이 대부분의 값들이 0~250000 값 사이에 존재하나 몇몇 이상 값에 의해 직관적이지 않은 그래프가 그려질 수 있다.
오른쪽의 그래프는 이와 같은 현상을 방지하기 위해 데이터를 정규화시킨 모습니다.
데이터의 전처리 과정에는 표준화와 정규화가 있다.
표준화는 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내며, 특정 범위에서 벗어난 값은 outlier라고 한다.

표준화식을 코드로 옮기면 다음과 같다.
Standardization = (data - np.mean(data)) / sqrt(np.sum(data - np.mean(data))^2) / np.count(data))
정규화는 데이터의 상대적 크기에 대한 영향을 줄이기 위해 0~1 사이의 값으로 표현한 것을 말한다.

정규화식을 코드로 옮기면 다음과 같다.
Normalization = (data - np.min(data, 0)) / (np.max(data, 0) - (np.min(data, 0)))
이와 같이 수치상의 그래프뿐만 아니라 얼굴, 문장 등을 판별하기 위한 경우에도 noisy data를 제거하는 것을 데이터 전처리라 한다.
Overfitting
모델을 학습시키기 위해서는 학습을 위한 일정량의 sample data가 필요하다.

만드는 과정에서 학습용 data를 통해 학습을 하며 새로운 data에 대한 정확도도 함께 높아져야 하는데,
학습용 data에 대한 정확도는 높은 반면, Test 과정에서 새로운 data를 받아들이면 오히려 정확도가 떨어지는 경우가 있다.

학습용 data에 대한 정확도만 높은 이러한 현상을 Overfitting이라고 한다.
가장 오른쪽 그래프의 경우 data에 따른 변화량이 크다. 이와 같은 경우가 overfit 된 경우이다.
Overfitting을 해결하는 방법 중 하나는 feature를 조절하는 것이다.
1. 더 많은 데이터를 학습시키거나,
2. 의미 있는 1차원 데이터로 feature를 감소시키거나,
#sklearn Code
from sklearn.decomposition import PCA
pca = decomposition.PcA(n_components=3)
pca.fit(X)
X = pca.transform(X)3. 위 두 가지 방법과는 반대로 가설이 너무 간단할 때 조금 더 세부적으로 조절한다.
또 다른 방법은 앞서 소개한 '정규화'이다.
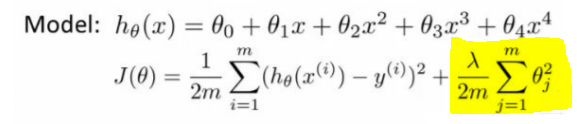
위의 노란 부분처럼 λ 값을 통해 모델의 평균값을 주면서 정규화 과정을 거쳐 overfitting을 해결할 수 있다.
이 경우 두 가지 방법이 있는데 L1 loss와 L2 loss이다. L1 loss의 경우 weight값을 0으로 만들어버리기 때문에,
이상치에 조금 더 주목하고자 하는 경우에는 L2 loss를 사용한다.
Data Sets

모델을 만들기 위해서는 일정량의 학습용 데이터를 이용해 학습을 시키고, 테스트용 데이터를 넣어 평가를 하게 된다.
왼쪽과 같이 학습 데이터와 연관이 없는 평가 데이터에 대해서는 제대로 평가할 수 없다. 따라서 오른쪽과 같은 데이터를 좋은 예시로 볼 수 있다.

데이터를 구성한 이후에는 모델의 성능 향상을 위한 과정이 필요하다.
Learning
학습 데이터를 준비한 뒤에는 학습을 해야 한다.
학습의 방법 중 Online과 Batch 두 가지 방법 사이에는 아래와 같은 차이점이 있다.


Fine Tuning과 Feature Extraction의 학습 방법 또한 서로 차이점이 있다.
Fine Tuning의 경우, Original Model에서 새로운 데이터를 통해 weight를 세밀하게 조정하도록 학습하는 것이다. Feature Extraction의 경우, 기존의 weight는 그대로 두고 새로운 레이어를 추가해 학습을 하는 것이다.
효율적인 모델을 만드는 방법에는 1x1 Convolution 이 있다.
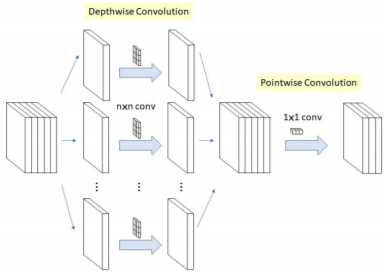
많은 경우 이 방법을 사용하고 있으며, 이 방법을 이용해 Channel 수를 조절할 수 있다. 또한, 파라미터 수가 감소하게 되고 이런 점을 통해 기존보다 많은 비선형성 활성화 함수를 사용하여 모델의 구성을 더 깊게할 수 있다.
마지막으로 Fashion MNIST-Image Classification을 통한 실습을 해보았다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
tf.random.set_seed(777)
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
plt.figure()
plt.imshow(train_images[3]) # 배열 네번째 'Dress'
plt.colorbar()
plt.grid(False)
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)'AI' 카테고리의 다른 글
| [ai-2team] 5. Relu, Weight Initialization, Dropout, Batch Normalization (0) | 2021.01.28 |
|---|---|
| [ai-2team] 4. Neural Networks (0) | 2021.01.27 |
| [ai-2team] 2. Multi-variable linear regression, Logistic regression, Softmax Classifier (0) | 2021.01.15 |
| [AI-3Team] 소프트맥스 회귀(Softmax Regression) 다중 클래스 분류 (0) | 2021.01.13 |
| [ai-1team] 6. Recurrent Neural Network (0) | 2021.01.08 |



